模型微调心得和踩坑指南
作者:🧑🚀 deadmau5v 发布于
我在上家公司和当前的多个项目中都用到了模型微调,今天把实战经验和踩坑点整理成一篇心得。
为什么要做微调?因为在不少特定任务里,只靠提示词很难长期稳定达标,而且在成本和速度上也不划算。几个常见场景:
结构化输出场景要求稳定输出 JSON 和固定字段,提示词很容易偶发失控(虽然Openrouter有json修复功能,但是成本较高);垂直领域场景有行业术语和业务规则,通用模型常常答偏细节;高并发在线场景为了降低延迟和单次推理成本,需要把长 Prompt 压缩成模型参数内化能力;客服、审核、质检这类稳定风格场景要求口径一致,仅靠 Prompt 很难跨版本保持稳定。
这篇文章按实战流程整理一套已落地的方法,从数据准备、算力选择、参数调优,到格式化输出和服务部署,讲讲我遇到的坑和如何解决他们的。
一、数据集准备
微调效果的上限通常由数据质量决定。数据格式建议优先采用 Alpaca(instruction / input / output),兼容性更好,后续做 SFT 和 DPO 的字段映射也更省事。
参考链接:LLaMA-Factory Alpaca 数据格式
开源数据集怎么找
开源数据集建议按任务反推去找,在 Hugging Face、Kaggle、ModelScope 这类平台先筛 License 和字段完整度,再做小样本抽检、去重和泄漏检查,确认能映射到 Alpaca 格式后再大规模清洗。
1. 核心策略与样本配比
不要盲目扩充数据量,应建立以错误类型驱动增量数据的机制。
| 样本类型 | 占比建议 | 作用 | 示例 |
|---|---|---|---|
| 正样本 (Golden) | 40% | 告诉模型什么是对的 | 高质量推理和标准格式回答 |
| 负样本 (Negative) | 20% | 告诉模型什么是错的 | 常见逻辑陷阱回答,在 DPO 阶段标记为 rejected |
| 边界样本 (Boundary) | 30% | 提升鲁棒性,划定能力边界 | 危险请求应拒绝,安全求助应回答 |
| 通用能力 (Generic) | 10% | 防止灾难性遗忘 | 保留少量通用对话与基础问答 |
2. 数据集准备技巧
人工标注:先做一批高质量种子数据(Seed Set),优先覆盖高频问题、业务关键流程和历史 bad case。这批数据不是追求数量,而是追求定义标准答案和边界行为。
克隆泛化:把人工标注样本做“同义改写 + 场景变体 + 噪声注入”,一条种子样本扩成多条训练样本,但语义和输出约束保持不变。比如改写用户语气、改写输入长度、插入无关噪声、替换实体名,模型就能学到稳定规则而不是背模板。
代码生成:对可程序化的任务(结构化抽取、SQL 生成、字段映射、规则分类)可以用脚本批量造数据,再用规则或单测自动验收。这样能快速补齐长尾场景,也能减少纯人工标注成本。
真实数据回流(最重要):把线上真实请求和失败样本持续回收,做脱敏、去重、聚类和重标注,再送入下一轮训练。这个环节通常是模型迭代速度最快的来源。
3. 人工标注如何落地
先写标注 SOP,再开始标注。SOP 里至少要写清楚四件事:什么算好答案、什么必须拒答、输出格式怎么写、常见错误怎么判。没有 SOP,数据会在多人协作中快速漂移。
如果你的任务字段比较特殊,建议用 v0 或 bolt.new 先快速生成一个轻量标注工具,把表单、预览、规则校验和快捷键按你的数据 schema 定制好,再导出到 Alpaca 格式;这样不用等完整平台搭建,也能快速适配特定数据集并显著提升标注速度。

标注时建议保留字段级元信息,比如 task_type、difficulty、domain、source、annotator、reviewer、version。后面做误差分析时,这些字段能直接定位是哪类样本在拖后腿。
抽检不要只看准确率,要重点看边界一致性。比如安全相关问题是否稳定拒答、结构化输出是否每次都能被 parser 通过。很多模型离线分数不错,但线上失败点都在这类细节上。
4. 把人工标注数据做克隆泛化
推荐把“人工标注 -> 克隆泛化”做成固定流水线:先选一批高质量种子样本,再用更强模型生成改写版本,然后用规则筛选,最后人工抽检。常见做法是每条种子样本扩 3-8 条变体,覆盖不同表达方式和噪声条件。
做克隆泛化时要特别注意一条:可以改输入表达,但不要改任务语义和答案契约。比如要求输出 JSON 的任务,所有变体都必须保持同样的字段约束,否则模型会学乱。
建议在数据中保留血缘字段,如 source_id、augment_type、augment_round。这样当某一轮训练效果变差时,可以快速定位是哪个泛化策略引入了噪声。
5. 代码生成数据:低成本补齐长尾
如果任务本身有确定性规则,尽量把“造数据 + 验数据”自动化。比如从真实 SQL 模板、接口 schema、业务枚举值里自动组合输入,再生成标准输出,通过脚本校验语法、字段和约束。
这一类数据特别适合补齐长尾 corner case:空值、字段缺失、异常格式、极端长度、冲突指令。人工很难系统覆盖,但脚本可以批量穷举。
6. 用 Langfuse 收集真实数据,驱动迭代(开源,可自部署)
推荐把线上数据采集接到 Langfuse,用它记录每次调用的 Prompt、上下文、模型输出、延迟、成本和用户反馈。这样你能持续拿到最真实的 bad case,而不是只依赖离线构造题。
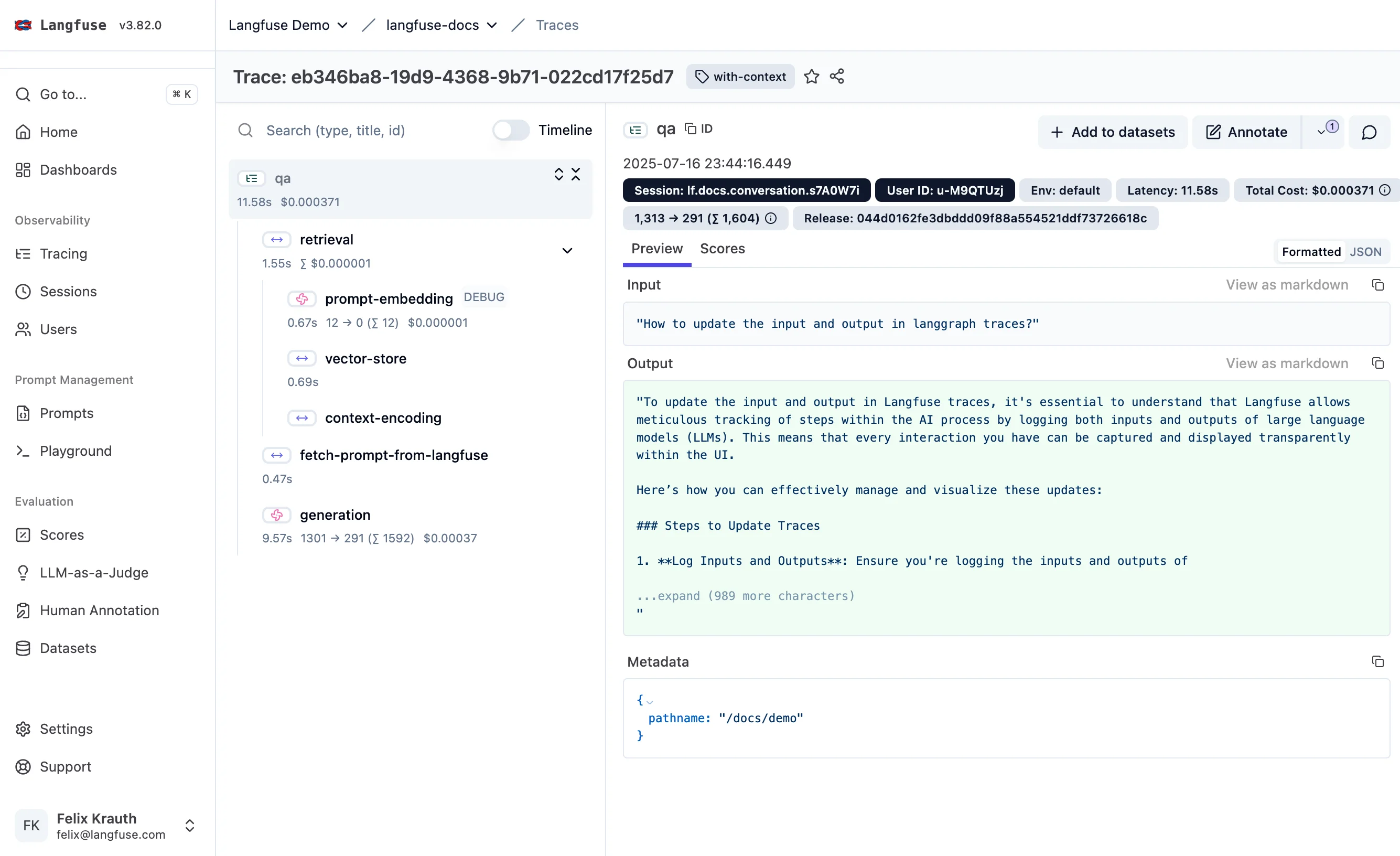
落地时可以按这个节奏做:线上埋点采集 -> 自动脱敏 -> 失败样本聚类 -> 人工复标 -> 回灌训练集 -> 离线评测 -> 小流量灰度。这个闭环每周跑一次,模型质量通常会稳定上升。
参考链接:Langfuse 官网 | Langfuse 文档
7. 数据闭环
把流程固定为 待验证 -> 验证集 -> 误差分析 -> 数据修订,并且把线上真实样本作为迭代主驱动。
待验证阶段处理新清洗和新回流的数据;验证集必须与训练集严格隔离,并长期保留困难样本;误差分析阶段不仅看总体分数,还要按任务类型、来源和难度拆分;数据修订阶段针对具体错误类型补数据,而不是盲目加量。
二、算力选型与环境
硬件选型尽量基于已正式发布且有公开实测的数据,不建议使用传闻参数作为训练基准。V100 在 2026 年也不再建议作为新模型微调主力,优先选择支持 BF16 与 Flash Attention 2 的架构(Ampere 及以上)。
如果你要更细地比较价格、稳定性和适用场景,可以看我之前的这篇文章:GPU 云平台调研,从传统云到 Serverless。
1. 推荐 GPU 配置
| 模型规模 | 推荐显卡(最低配置) | 推荐显卡(生产力配置) | 备注 |
|---|---|---|---|
| 7B / 8B | RTX 4090 (24G) | A100 / A800 (80G) | 4090 适合 LoRA/QLoRA,全参建议 A100 |
| 14B / 20B | 2x RTX 4090 | 2x A100 (80G) | 多卡训练关注 PCIe 带宽,NVLink 更优 |
| 32B / 70B | 4x RTX 4090 | 4x-8x H100 / H800 | 大模型更依赖服务器级互联与显存 |
2. 关键环境检查
连接服务器后先验证 CUDA 与算力:
python -c "import torch; print(torch.cuda.get_device_capability(), torch.version.cuda)"
# 目标:CUDA >= 11.8,显卡算力 >= 8.0三、LLaMA-Factory 训练实战
1. 部署与安装
建议锁定仓库版本,避免最新提交引入不稳定行为。
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
conda create -n llama_factory python=3.10 -y
conda activate llama_factory
pip install -e ".[torch,metrics]"2. 关键参数设置
- 学习率策略:
LoRA从2e-4起步,若 Loss 震荡且不下降,降至5e-5;全参微调从1e-5或更低起步,使用cosine衰减,warmup_steps设总步数的 3%-5%。 - 批次策略:
避免过小的单卡批次导致梯度不稳,通过梯度累积把等效批次凑到
64或128。 - 等效批次公式:
等效 Batch Size = 单卡 Batch Size * 显卡数 * 梯度累积步数。 - LoRA Rank 策略:
通用任务常用
rank=16或32;学习全新知识体系时可尝试64或128,并让alpha约等于2 * rank。
3. 数据集注册
建议增加 sha1 校验,避免数据被静默修改。
{
"my_custom_data": {
"file_name": "data_v2_badcase_fix.json",
"sha1": "optional_sha1_hash",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
}四、特定需求:格式化输出
在工业场景里,很多链路对 Token 成本和 JSON 严格格式非常敏感。只靠 Prompt 约束往往不够,建议把格式约束前移到数据处理和训练目标中。
1. 智能截断与序列打包
- 截断策略:
不要使用一刀切截断。JSON 任务一旦截断到尾部,常见问题是丢失闭合符号
},直接导致下游解析失败。 - 长文本处理: 长文本优先使用 Sliding Window 切分成多条样本,而不是硬裁剪单条样本。
- 问答任务兜底: 如果必须截断,优先保证输出段完整,尤其是 JSON 的闭合结构与转义字符。
- 序列打包:
建议开启
packing=True,把多条短样本拼到同一 Sequence(用<eos>分隔)。通常能明显提升吞吐,同时减少模型无止境续写的概率。
2. 强格式约束:RLHF + JSON 解析奖励
如果业务强依赖结构化输出(例如 Function Calling、结构化抽取、RAG 回填),SFT 只能让模型模仿格式,无法稳定保证语法正确。
推荐流程:
- 冷启动 SFT: 先准备少量高质量 JSON 样本(例如 500 条),让模型形成基础格式偏好。
- 强化学习对齐: 用规则脚本做奖励函数,不依赖人工逐条打分。
import json
def json_format_reward(response_text):
try:
parsed = json.loads(response_text)
if "reasoning" in parsed and "answer" in parsed:
return 1.0
return 0.5
except json.JSONDecodeError:
return -1.0
except Exception:
return -0.5- 训练目标: 让模型把概率质量集中在可解析、字段完整的 JSON 结构上,减少前后缀废话。
- 轻量替代(不跑 PPO): 可用 Best-of-N + Rejection Sampling。让模型一次生成 N 份候选,脚本自动挑选可解析样本作为正样本,失败样本可转为 DPO 负样本。
实践经验:
- 仅做 SFT 时,模型常出现
Here is the JSON:这类冗余前缀。 - 加入格式奖励或拒绝采样后,纯 JSON 输出稳定性会明显提升。
- 单卡 4090 显存紧张时,优先考虑 DPO 格式纠错数据集,成本通常低于 PPO。
五、评估与 Bad Case 分析
只看 Loss 曲线不够,Loss 下降只能证明背诵能力提升,不等于真实效果提升。
- 训练中评估:
设置
eval_steps(如每 100 步),同时观察训练集和验证集 Loss。若训练 Loss 下降、验证 Loss 上升,应及时早停。 - 生成式评估: 使用模型未见过的测试题,做微调前后对比评测。
- LLM-as-a-Judge: 可使用更强模型做结构化评分,再结合人工审查关键边界 Case。
六、导出与服务化
1. LoRA 融合
部署前建议将 LoRA 权重合并回基座模型,减少推理时的额外开销。
llamafactory-cli export \
--model_name_or_path <基座模型路径> \
--adapter_name_or_path <微调后 checkpoint 路径> \
--template <模板名称> \
--finetuning_type lora \
--export_dir <合并模型输出路径> \
--export_size 5 \
--export_device cpu2. vLLM 部署
新版 vLLM 建议显式指定 chat-template(如果模型未内置)。
vllm serve <合并后的模型路径> \
--served-model-name custom-model-v1 \
--dtype bfloat16 \
--max-model-len 8192 \
--gpu-memory-utilization 0.95 \
--chat-template ./chat_template.jinja \
--trust-remote-code如果模型已内置模板,可以移除 --chat-template 参数。